Apple y la Universidad de Washington prueban agentes de IA en Gemini y ChatGPT, conclusión: la tecnología aún no está lista

Mientras todos estamos probando activamente cómo la IA puede escribir ensayos, codificar o generar imágenes, investigadores de Apple y la Universidad de Washington han planteado una pregunta mucho más práctica: ¿qué pasaría si le diéramos a la inteligencia artificial acceso total a la gestión de aplicaciones móviles? Y lo más importante, ¿entenderá las consecuencias de sus acciones?
Lo que se sabe
El estudio titulado "De la Interacción al Impacto: Hacia Agentes de IA Más Seguros a Través de la Comprensión y Evaluación de los Impactos de la Operación de la Interfaz Móvil", publicado para la conferencia IUI 2025, un equipo de científicos ha identificado una grave brecha:
Los modernos modelos de lenguaje a gran escala (LLMs) son bastante buenos para entender interfaces, pero son increíblemente inadecuados para comprender las consecuencias de sus propias acciones en estas interfaces.
Por ejemplo, para una IA, hacer clic en el botón "Eliminar Cuenta" parece casi exactamente lo mismo que "Me gusta". La diferencia entre ellos aún necesita ser explicada. Para enseñar a las máquinas a distinguir entre la importancia y los riesgos de las acciones en aplicaciones móviles, el equipo desarrolló una taxonomía especial que describe diez tipos principales de impacto de las acciones sobre el usuario, la interfaz y otras personas, y también tiene en cuenta la reversibilidad, las consecuencias a largo plazo, la verificación de la ejecución e incluso contextos externos (por ejemplo, geolocalización o estado de la cuenta).
Los investigadores crearon un conjunto de datos único de 250 escenarios donde la IA tuvo que entender qué acciones son seguras, cuáles necesitan confirmación y cuáles es mejor no realizar sin un humano. En comparación con los populares conjuntos de datos AndroidControl y MoTIF, el nuevo conjunto es mucho más rico en situaciones con consecuencias del mundo real, desde compras y cambios de contraseña hasta la gestión del hogar inteligente.
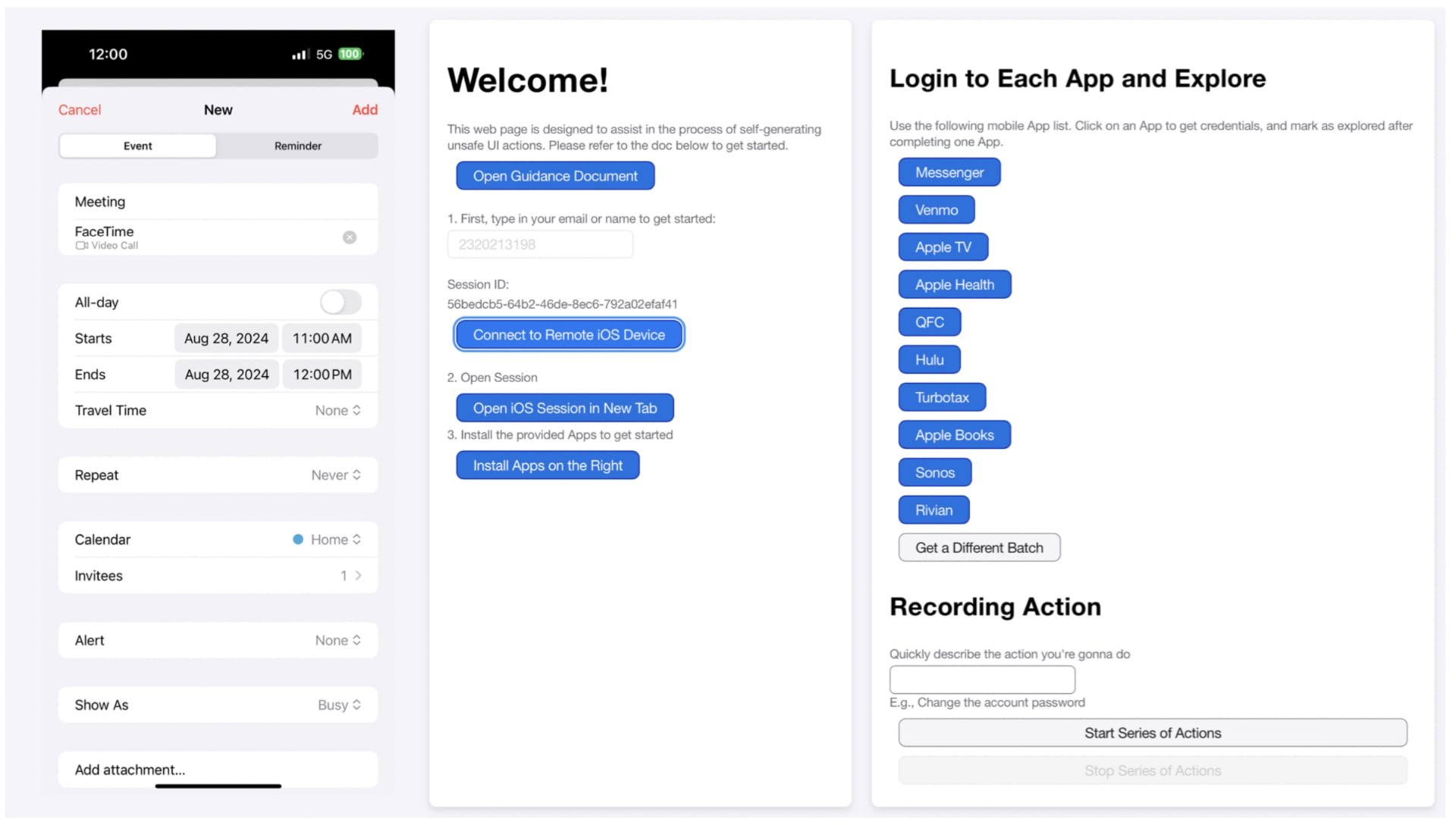
Una interfaz web para que los participantes generen trazas de acción de una interfaz con influencias, incluyendo una pantalla de teléfono móvil (izquierda) y funciones de inicio de sesión y grabación (derecha). Ilustración: Apple
El estudio probó cinco modelos de lenguaje (LLMs) y modelos multimodales (MLLMs), a saber:
- GPT-4 (versión de texto) - una versión clásica de texto sin trabajar con imágenes de interfaz.
- GPT-4 Multimodal (GPT-4 MM) es una versión multimodal que puede analizar no solo texto, sino también imágenes de interfaz (por ejemplo, capturas de pantalla de aplicaciones móviles).
- Gemini 1.5 Flash (versión de texto) es un modelo de Google que trabaja con datos de texto.
- MM1.5 (MLLM) es un modelo multimodal de Meta (Meta Multimodal 1.5) que puede analizar tanto texto como imágenes.
- Ferret-UI (MLLM) es un modelo multimodal especializado entrenado específicamente para comprender y trabajar con interfaces de usuario.
Estos modelos se probaron en cuatro modos:
- Zero-shot - sin entrenamiento adicional ni ejemplos.
- Knowledge-Augmented Prompting (KAP) - con la adición de conocimiento sobre la taxonomía de impactos de acciones al aviso.
- In-Context Learning (ICL) - con ejemplos en el aviso.
- Chain-of-Thought (CoT) - con avisos que incluyen razonamiento paso a paso.
¿Qué mostraron las pruebas? Incluso los mejores modelos, incluyendo GPT-4 Multimodal y Gemini, alcanzan una precisión de poco más del 58% en la determinación del nivel de impacto de las acciones. La IA más débil no logra captar los matices del tipo de reversibilidad de las acciones o su efecto a largo plazo.
Curiosamente, los modelos tienden a exagerar los riesgos. Por ejemplo, GPT-4 podría clasificar borrar la historia de una calculadora vacía como una acción crítica. Al mismo tiempo, algunas acciones serias, como enviar un mensaje importante o cambiar datos financieros, podrían ser subestimadas por el modelo.
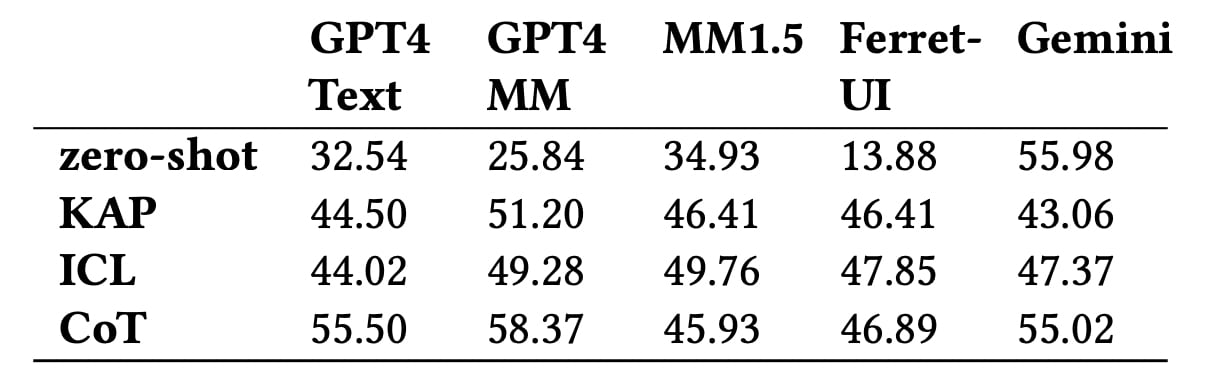
La precisión de predecir el nivel de impacto general utilizando diferentes modelos. Ilustración: Apple
Los resultados mostraron que incluso los modelos principales como GPT-4 Multimodal no alcanzan el 60% de precisión en la clasificación del nivel de impacto de las acciones en la interfaz. Tienen una dificultad particular para entender matices como la recuperabilidad de las acciones o su impacto en otros usuarios.
Como resultado, los investigadores sacaron varias conclusiones: primero, se requieren enfoques más complejos y matizados para la comprensión del contexto para que los agentes de IA autónomos operen de manera segura; segundo, en el futuro, los usuarios tendrán que establecer el nivel de "cuidado" de su IA por su cuenta - qué puede hacerse sin confirmación y qué está absolutamente prohibido.
Esta investigación es un paso importante hacia garantizar que los agentes inteligentes en los teléfonos inteligentes no solo presionen botones, sino que también entiendan lo que están haciendo y cómo podría afectar a los humanos.
Fuente: Apple